General Sarracenia Concepts
This document describes abstractions underlying Sarracenia. It isn't clear how directly applicable this information is to normal usage, but it seems this information should be available somewhere.
Introduction
Sarracenia pumps form a network. The network uses amqp brokers as a transfer manager which sends advertisements in one direction and report messages in the opposite direction. Administrators configure the paths that data flows through at each pump, as each broker acts independently, managing transfers from transfer engines it can reach, with no knowledge of the overall network. The locations of pump and the directions of traffic flow are chosen to work with permitted flows. Ideally, no firewall exceptions are needed.
Sarracenia does no data transport. It is a management layer to co-ordinate the use of transport layers. So to get a running pump, actual transport mechanisms need to be set up as well. The two mechanisms currently supported are web servers, and SFTP. In the simplest case, all of the components are on the same server, but there is no need for that. The broker could be on a different server from both ends of a given hop of a data transfer.
The best way for data transfers to occur is to avoid polling. It is more efficient if writers can be coaxed into emitting appropriate sr_post messages. Similarly, when delivering, it is ideal if the receivers use sr_subscribe, and an on_file plugin to trigger their further processing, so that the file is handed to them without polling. This is the most efficient way of working, but it is understood that not all software can be made co-operative. Tools to poll in order to start transport flows are sr_poll, and sr_watch.
Generally speaking, Linux is the main deployment target, and the only platform on which server configurations are deployed. Other platforms are used as client end points. This isn´t a limitation, it is just what is used and tested. Implementations of the pump on Windows should work, they just are not tested.
Mapping AMQP Concepts to Sarracenia
One thing that is safe to say is that one needs to understand a bit about AMQP to work with Sarracenia. AMQP is a vast and interesting topic in it's own right. No attempt is made to explain all of it here. This section just provides a little context, and introduces only background concepts needed to understand and/or use Sarracenia. For more information on AMQP itself, a set of links is maintained at the Metpx web site but a search engine will also reveal a wealth of material.
An AMQP Server is called a Broker. Broker is sometimes used to refer to the software, other times server running the broker software (same confusion as web server.) In the above diagram, AMQP vocabulary is in Orange, and Sarracenia terms are in blue. There are many different broker software implementations. We use rabbitmq. We are not trying to be rabbitmq specific, but management functions differ between implementations.
- Queues are usually taken care of transparently, but you need to know
- A Consumer/subscriber creates a queue to receive messages.
- Consumer queues are bound to exchanges (AMQP-speak)
- An exchange is a matchmaker between publisher and consumer queues.
- A message arrives from a publisher.
- message goes to the exchange, is anyone interested in this message?
- in a topic based exchange, the message topic provides the exchange key.
- interested: compare message key to the bindings of consumer queues.
- message is routed to interested consumer queues, or dropped if there aren't any.
- Multiple processes can share a queue, they just take turns removing messages from it.
- This is used heavily for sr_sarra and sr_subcribe multiple instances.
- Queues can be durable, so even if your subscription process dies,
- if you come back in a reasonable time and you use the same queue, you will not have missed any messages.
- How to Decide if Someone is Interested.
- For Sarracenia, we use (AMQP standard) topic based exchanges.
- Subscribers indicate what topics they are interested in, and the filtering occurs server/broker side.
- Topics are just keywords separated by a dot. wildcards: # matches anything, * matches one word.
- We create the topic hierarchy from the path name (mapping to AMQP syntax)
- Resolution & syntax of server filtering is set by AMQP. (. separator, # and * wildcards)
- Server side filtering is coarse, messages can be further filtered after download using regexp on the actual paths (the reject/accept directives.)
- topic prefix? We start the topic tree with fixed fields
- v02 the version/format of sarracenia messages.
- post ... the message type, this is an announcement of a file (or part of a file) being available.
Sarracenia is an AMQP Application
MetPX-Sarracenia is only a light wrapper/coating around AMQP.
- A MetPX-Sarracenia data pump is a python AMQP application that uses a (rabbitmq) broker to co-ordinate SFTP and HTTP client data transfers, and accompanies a web server (apache) and sftp server (openssh), often on the same user-facing address.
- Wherever reasonable, we use their terminology and syntax.
If someone knows AMQP, they understand. If not, they can research.
- Users configure a broker, instead of a pump.
- by convention, the default vhost '/' is always used. (did not feel the need to use other vhosts yet)
- users explicitly can pick their queue names.
- users set subtopic,
- topics with dot separator are minimally transformed, rather than encoded.
- queue durable.
- we use message headers (AMQP-speak for key-value pairs) rather than encoding in JSON or some other payload format.
- reduce complexity through conventions.
- use only one type of exchanges (Topic), take care of bindings.
- naming conventions for exchanges and queues.
- exchanges start with x. - xs_Weather - the exchange for the source (amqp user) named Weather to post messages - xpublic -- exchange used for most subscribers.
- queues start with q_
Flow Through Pumps
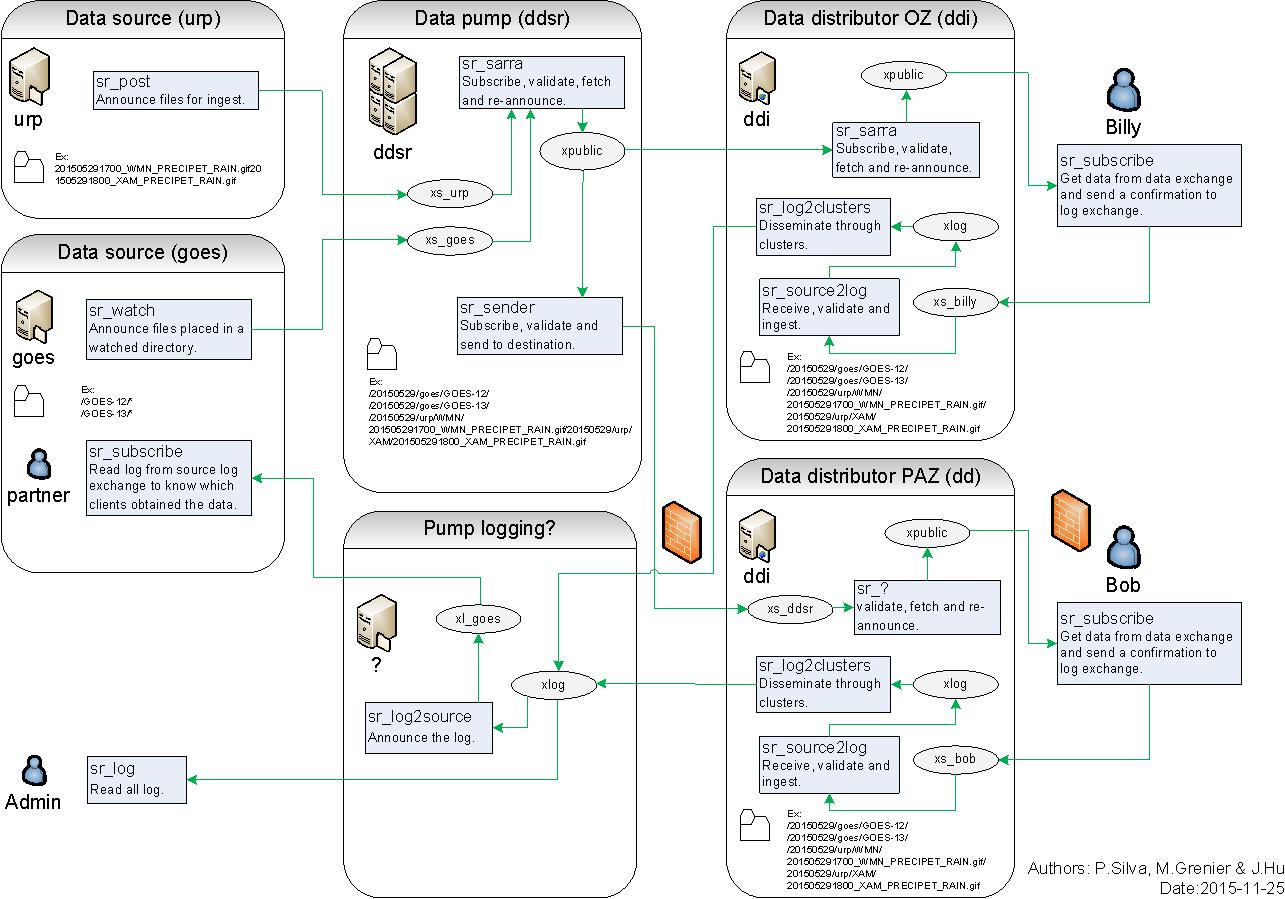
A description of the conventional flow of messages through exchanges on a pump:
- subscribers usually bind to the xpublic exchange to get the main data feed. this is the default in sr_subscribe.
- A user named Alice will have two exchanges:
- xs_Alice the exhange where Alice posts her file notifications and report messages.(via many tools)
- xr_Alice the exchange where Alice reads her report messages from (via sr_report)
- usually sr_sarra will read from xs_alice, retrieve the data corresponding to Alice´s post message, and make it available on the pump, by re-announcing it on the xpublic exchange.
- sr_winnow may pull from xs_alice instead, but follows the same pattern as sr_sarra.
- usually, sr_audit --users will cause rr_alice2xreport shovel configurations to read xs_alice and copy the report messages onto the private xreport exchange.
- Admins can point sr_report at the xreport exchange to get system-wide monitoring. Alice will not have permission to do that, she can only look at xl_Alice, which should have the report messages pertinent to her.
- rr_xreport2source shovel configurations auto-generated by sr_audit look at messages for the local Alice user in xreport, and sends them to xl_Alice.
The purpose of these conventions is to encourage a reasonably secure means of operating. If a message is taken from xs_Alice, then the process doing the reading is responsible for ensuring that it is tagged as coming from Alice on this cluster. This prevents certain types of ´spoofing´ as messages can only be posted by proper owners.
Users and Roles
Usernames for pump authentication are significant in that they are visible to all. They are used in the directory path on public trees, as well as to authenticate to the broker. They need to be understandable. They are often wider scope than a person... perhaps call them 'Accounts'. It can be elegant to configure the same usernames for use in transport engines.
All Account names should be unique, but nothing will avoid clashes when sources originate from different pump networks, and clients at different destinations. In practice, name clashes are addressed by routing to avoid two different sources' with the same name having their data offerings combined on a single tree. On the other hand, name clashes are not always an error. Use of a common source account name on different clusters may be used to implement folders that are shared between the two accounts with the same name.
Pump users are defined with the declare option. Each option starts with the declare keyword, followed by the specified role, and lastly the user name which has that role. role can be one of:
- subscriber
A subscriber is user that can only subscribe to data and report messages. Not permitted to inject data. Each subscriber gets an xs_<user> named exchange on the pump, where if a user is named Acme, the corresponding exchange will be xs_Acme. This exchange is where an sr_subscribe process will send it's report messages.
By convention/default, the anonymous user is created on all pumps to permit subscription without a specific account.
- source
A user permitted to subscribe or originate data. A source does not necessarily represent one person or type of data, but rather an organization responsible for the data produced. So if an organization gathers and makes available ten kinds of data with a single contact email or phone number for questions about the data and it's availability, then all of those collection activities might use a single 'source' account.
Each source gets a xs_<user> exchange for injection of data posts, and, similar to a subscriber, to send report messages about processing and receipt of data. Each source is able to view all of the messages for data it has injected, but the location where all of these messages are available varies according to administrator configuration of report routing. A source may inject data on pumpA, but may subscribe to reports on a different pump. The reports corresponding to the data the source injected are written in exchange xl_<user>.
When data is first injected, the path is modified by sarracenia to prepend a fixed upper part of the directory tree. The first level directory is the day of ingest into the network in YYYYMMDD format. The second level directory is the source name. So for a user Alice, injecting data on May 4th, 2016, the root of the directory tree is: 20160504/Alice. Note that all pumps are expected to run in the UTC timezone (widely, but inaccurately, referred to as GMT.)
There are daily directories because there is a system-wide life-time for data, it is deleted after a standard number of days, data is just deleted from the root.
Since all clients will see the directories, and therefore client configurations will include them. it would be wise to consider the account name public, and relatively static.
Sources determine who can access their data, by specifying which cluster to send the data to.
- feeder
- a user permitted to subscribe or originate data, but understood to represent a pump. this local pump user would be used to, run processes like sarra, report routing shovels, etc...
- admin
- a user permitted to manage the local pump. It is the real rabbitmq-server administrator. The administrator runs sr_audit to create/delete exchanges, users, or clean unused queues... etc.
Example of a complete valid admin.conf, for a host named blacklab
cluster blacklab admin amqps://hbic@blacklab/ feeder amqps://feeder@blacklab/ declare source goldenlab declare subscriber anonymous
A corresponding credentials.conf would look like:
amqps://hbic:hbicpw@blacklab/ amqps://feeder:feederpw@blacklab/ amqps://goldenlab:puppypw@blacklab/ amqps://anonymous:anonymous@blacklab/
Transport Engines
Transport engines are the data servers queried by subscribers, by the end users, or other pumps. The subscribers read the notices and fetch the corresponding data, using the indicated protocol. The software to serve the data can be either SFTP or HTTP (or HTTPS.) For specifics of configuring the servers for use, please consult the documentation of the servers themselves. Also note that additional protocols can be enabled through the use of do_ plugins, as described in the Programming Guide.
IPv6
A sample pumps was implemented on a small VPS with IPv6 enabled. A client from far away connected to the rabbitmq broker using IPv6, and the subscription to the apache httpd worked without issues. It just works. There is no difference between IPv4 and IPv6 for sarra tools, which are agnostic of IP addresses.
On the other hand, one is expected to use hostnames, since use of IP addresses will break certificate use for securing the transport layer (TLS, aka SSL) No testing of ip addresses in URLs (in either IP version) has been done.
Pump Designs
There are many different arrangements in which sarracenia can be used.
- Dataless
- where one runs just sarracenia on top of a broker with no local transfer engines. This is used, for example to run sr_winnow on a site to provide redundant data sources.
- Standalone
- the most obvious one, run the entire stack on a single server, openssh and a web server as well the broker and sarra itself. Makes a complete data pump, but without any redundancy.
- Switching/Routing
- Where, in order to achieve high performance, a cluster of standalone nodes are placed behind a load balancer. The load balancer algorithm is just round-robin, with no attempt to associate a given source with a given node. This has the effect of pumping different parts of large files through different nodes. So one will see parts of files announced by such pump, to be re-assembled by subscribers.
- Data Dissemination
- Where in order to serve a large number of clients, multiple identical servers, each with a complete mirror of data
- FIXME:
- ok, opened big mouth, now need to work through the examples.
Dataless or S=0
A configuration which includes only the AMQP broker. This configuration can be used when users have access to disk space on both ends and only need a mediator. This is the configuration of sftp.science.gc.ca, where the HPC disk space provides the storage so that the pump does not need any, or pumps deployed to provide redundant HA to remote data centres.
FIXME: sample configuration of shovels, and sr_winnow (with output to xpublic) to allow subscribers in the SPC to obtain data from either edm or dor.
Note that while a configuration can be dataless, it can still make use of rabbitmq clustering for high availability requirements (see rabbitmq clustering below.)
Winnowed Dataless
Another example of a dataless pump would be to provide product selection from two upstream sources using sr_winnow. The sr_winnow is fed by shovels from upstream sources, and the local clients just connect to this local pump. sr_winnow takes care of only presenting the products from the first server to make them available. One would configure sr_winnow to output to the xpublic exchange on the pump.
Local subscribers just point at the output of sr_winnow on the local pump. This is how feeds are implemented in the Storm prediction centres of ECCC, where they may download data from whichever national hub produces data first.
Dataless With Sr_poll
The sr_poll program can verify if products on a remote server are ready or modified. For each of the product, it emits an announcement on the local pump. One could use sr_subscribe anywhere, listen to announcements and get the products (privided the having the credentials to access it)
Standalone
In a standalone configuration, there is only one node in the configuration. It runs all components and shares none with any other nodes. That means the Broker and data services such as sftp and apache are on the one node.
One appropriate usage would be a small non-24x7 data acquisition setup, to take responsibility of data queueing and transmission away from the instrument. It is restarted when the opportunity arises. It is just a matter of installing and configuring all a data flow engine, a broker, and the package itself on a single server. The ddi systems are generally configured this way.
Switching/Routing
In switching/routing configuration, there is a pair of machines running a single broker for a pool of transfer engines. So each transfer engine´s view of the file space is local, but the queues are global to the pump.
Note: On such clusters, all nodes that run a component with the same config file create by default an identical queue_name. Targetting the same broker, it forces the queue to be shared. If it should be avoided, the user can just overwrite the default queue_name inserting ${HOSTNAME}. Each node will have its own queue, only shared by the node instances. ex.: queue_name q_${BROKER_USER}.${PROGRAM}.${CONFIG}.${HOSTNAME} )
Often there is internal traffic of data acquired before it is finally published. As a means of scaling, often transfer engines will also have brokers to handle local traffic, and only publish final products to the main broker. This is how ddsr systems are generally configured.
Security Considerations
This section is meant to provide insight to those who need to perform a security review of the application prior to implementation.
Client
All credentials used by the application are stored in the ~/.config/sarra/credentials.conf file, and that file is forced to 600 permissions.
Server/Broker
Authentication used by transport engines is independent of that used for the brokers. A security assessment of rabbitmq brokers and the various transfer engines in use is needed to evaluate the overall security of a given deployment.
The most secure method of transport is the use of SFTP with keys rather than passwords. Secure storage of sftp keys is covered in documentation of various SSH or SFTP clients. The credentials file just points to those key files.
For sarracenia itself, password authentication is used to communicate with the AMQP broker, so implementation of encrypted socket transport (SSL/TLS) on all broker traffic is strongly recommended.
Sarracenia users are actually users defined on rabbitmq brokers. Each user Alice, on a broker to which she has access:
- has an exchange xs_Alice, where she writes her postings, and reads her logs from.
- has an exchange xr_Alice, where she reads her report messages.
- can configure (read from and acknowledge) queues named qs_Alice_.* to bind to exchanges
- Alice can create and destroy her own queues, but no-one else's.
- Alice can only write to her exchange (xs_Alice),
- Exchanges are managed by the administrator, and not any user.
- Alice can only post data that she is publishing (it will refer back to her)
Alice cannot create any exchanges or other queues not shown above.
Rabbitmq provides the granularity of security to restrict the names of objects, but not their types. Thus, given the ability to create a queue named q_Alice, a malicious Alice could create an exchange named q_Alice_xspecial, and then configure queues to bind to it, and establish a separate usage of the broker unrelated to sarracenia.
To prevent such mis-use, sr_audit is a component that is invoked regularly looking for mis-use, and cleaning it up.
Input Validation
Users such as Alice post their messages to their own exchange (xs_Alice). Processes which read from user exchanges have a responsibility for validation. The process that reads xs_Alice (likely an sr_sarra) will overwrite any source or cluster heading written into the message with the correct values for the current cluster, and the user which posted the message.
The checksum algorithm used must also be validated. The algorithm must be known. Similarly, if there is a malformed header of some kind, it should be rejected immediately. Only well-formed messages should be forwarded for further processing.
In the case of sr_sarra, the checksum is re-calculated when downloading the data, it ensures it matches the message. If they do not match, an error report message is published. If the recompute_checksum option is True, the newly calculated checksum is put into the message. Depending on the level of confidence between a pair of pumps, the level of validation may be relaxed to improve performance.
Another difference with inter-pump connections, is that a pump necessarily acts as an agent for all the users on the remote pumps and any other pumps the pump is forwarding for. In that case, the validation constraints are a little different:
- source doesn´t matter. (feeders can represent other users, so do not overwrite.)
- ensure cluster is not local cluster (as that indicates either a loop or misuse.)
If the message fails the non-local cluster test, it should be rejected, and logged (FIME: published ... hmm... clarify)
- FIXME:
- if the source is not good, and the cluster is not good... cannot report back. so just log locally?
Privileged System Access
Ordinary (sources, and subscribers) users operate sarra within their own permissions on the system, like an scp command. The pump administrator account also runs under a normal linux user account and, given requires privileges only on the AMQP broker, but nothing on the underlying operating system. It is convenient to grant the pump administrator sudo privileges for the rabbitmqctl command.
The may be a single task which must operate with privileges: cleaning up the database, which is an easily auditable script that must be run on a regular basis. If all acquisition is done via sarra, then all of the files will belong to the pump administrator, and privileged access is not required for this either.
The General Algorithm
All of the components that subscribe (subscribe, sarra, sender, shovel, winnow) share substantial code and differ only in default settings.
| PHASE | DESCRIPTION |
| List | Get information about an initial list of files from: a queue, a directory, a polling script. |
| Filter | Reduce the list of files to act on. Apply accept/reject clauses Check duplicate receipt cache run on_msg scripts |
| Do | process the message by downloading or sending run do_send,do_download run on_part,on_file (download only) |
| Post | run on_post scripts Post announcement of file downloads/sent to post_broker |
| Report | Post report of action to origin (to inform source) |
The main components of the python implementation of Sarracenia all implement the same algorithm described above. The algorithm has various points where custom processing can be inserted using small python scripts called on_*, do_*.
The components just have different default settings:
| Component | Use of the algorithm |
sr_subscribe Download file from a pump. If the local host is a pump, post the downloaded file. |
List=read from queue Filter Do=Download Post=optional Report=optional |
sr_poll Find files on other servers to post to a pump. |
List=run do_poll script Filter Do=nil Post=yes Report=no |
sr_shovel/sr_winnow Move posts or reports around. |
List=read from queue Filter (shovel cache=off) Do=nil Post=yes Report=optional |
sr_post/watch Find file on a local server to post |
List=read file system Filter Do=nil Post=yes Report=no |
sr_sender Send files from a pump. If remote is also a pump, post the sent file there. |
List=read queue Filter Do=sendfile Post=optional Report=optional |
Components are easily composed using AMQP brokers, which create elegant networks of communicating sequential processes. (in the Hoare sense)
Glossary
Sarracenia documentation uses a number of words in a particular way. This glossary should make it easier to understand the rest of the documentation.
- Source
Someone who wants to ship data to someone else. They do that by advertise a trees of files that are copied from the starting point to one or more pumps in the network. The advertisement sources produce tell others exactly where and how to download the files, and Sources have to say where they want the data to go to.
Sources use programs like sr_post.1, sr_watch.1, and sr_poll(1) to create their advertisements.
- Subscribers
are those who examine advertisements about files that are available, and download the files they are interested in.
Subscribers use sr_subscribe(1)
- Post, Notice, Notification, Advertisement, Announcement
- These are AMQP messages build by sr_post, sr_poll, or sr_watch to let users know that a particular file is ready. The format of these AMQP messages is described by the sr_post(7) manual page. All of these words are used interchangeably. Advertisements at each step preserve the original source of the posting, so that report messages can be routed back to the source.
- Report messages
- These are AMQP messages (in sr_report(7) format) built by consumers of messages, to indicate what a given pump or subscriber decided to do with a message. They conceptually flow in the opposite direction of notifications in a network, to get back to the source.
- Pump or broker
- A pump is a host running Sarracenia, a rabbitmq AMQP server (called a broker in AMQP parlance) The pump has administrative users and manage the AMQP broker as a dedicated resource. Some sort of transport engine, like an apache server, or an openssh server, is used to support file transfers. SFTP, and HTTP/HTTPS are the protocols which are fully supported by sarracenia. Pumps copy files from somewhere, and write them locally. They then re-advertised the local copy to it's neighbouring pumps, and end user subscribers, they can obtain the data from this pump.
For end users, a pump and a broker is the same thing for all practical purposes. When pump administrators configure multi-host clusters, however, a broker might be running on two hosts, and the same broker could be used by many transport engines. The entire cluster would be considered a pump. So the two words are not always the same.
- Dataless Pumps
- There are some pumps that have no transport engine, they just mediate transfers for other servers, by making messages available to clients and servers in their network area.
- Dataless Transfers
- Sometimes transfers through pumps are done without using local space on the pump.
- Pumping Network
- A number of interconnects servers running the sarracenia stack. Each stack determines how it routes items to the next hop, so the entire size or extent of the network may not be known to those who put data into it.
- Network Maps
- Each pump should provide a network map to advise users of the known destination that they should advertise to send to. FIXME undefined so far.